
In the previous two posts, I described hill climbing and simulated annealing as ways of breaking substitution ciphers where we can't make good initial guesses of the key. I said that simulated annealing, compared to hillclimbing, is more likely to find a good solution and is less likely to get stuck on some locally-good but globally-poor solution. In this post, I'll test the accuracy of those claims.
Experimental design
The basic idea is simple: I'll take a random chunk of text from the Complete Works of Sherlock Holmes, create a random mapping of plaintext letters to ciphertext letters (a random key), and encipher the text with that key. I'll then see if hillclimbing or simulated annealing are able to recover the original text from the given ciphertext.
I'll do that many, many times to see how often each algorithm succeeds. As always, you can find the code for this on Github.
Measuring success
One slight wrinkle in this experiment is determining what counts as "success". The cipher breaking systems evaluate their scores with a simple n-gram language model. However, there can be occasions where the best-scoring substitution isn't the right one. For instance, if a plaintext contains many uses of the word majesty and no or few zs, the algorithms will try to decipher that word as mazesty because mazes occurs more often in English than majes.
This means we have to judge success of of the decipherment by looking at the key it produces rather than the proposed plaintext. But how can we score the key?
The key is a mapping from plaintext letters of the alphabet to ciphertext letters of the alphabet. That gives us something like
| Plaintext alphabet | a | b | c | d | ... |
|---|---|---|---|---|---|
| Actual ciphertext alphabet | g | e | p | j | ... |
| Proposed ciphertext alphabet | g | e | l | j | ... |
So we can score the proposed ciphertext alphabet by counting how many letters are in the same order as in the actual ciphertext alphabet. Conveniently, this is implemented as the the Kendall rank correlation measure (also known as Kendall's τ), and implemented as the function kendalltau in the scipy.stats library.
The experiments
There are a few more things we can experiment with, in addition to the core experiment of hillclimbing vs simulated annealing.
While we can use Kendall's τ to tell whether we've found the right key, the codebreaking algorithm only knows about the n-gram score to determine the best key. That means we can see which n-gram score is better; I'll compare unigrams with trigrams.
In simulated annealing, the algorithm will sometimes choose a lower-scoring solution over its existing solution. How likely this is depends on both how much worse the alternative is, and the current temperature used by the algorithm. Higher temperatures make the algorithm more likely to choose a worse solution; this could lead the algorithm better to explore the range of possible cipher keys, or it could prevent the algorithm making any progress in the early part of its run.
Another variation in the algorithm is how the existing key is changed. We can generate a new key from the current one by swapping two letters. But which two letters to swap? One method is to pick two letters uniformly at random, regardless of where they are in the key. Another method is to assume that the current key is mostly correct, and that we should swap two nearby letters. In these experiments, I chose "nearby" by sampling from a Gaussian (normal, bell-shaped) distribution.
A final thing to look at is the initial key. The key is the complete mapping from each plaintext letter to each ciphertext letter. We could create this mapping entirely randomly, with all mappings equally likely. Or, we could attempt to give a head start to the search for the key, but mapping the most frequent plaintext letters to the most frequent ciphertext lettters.
This gives us five parameters to vary, and we can test combinations of all of them to see which works best.
- Hillclimbing vs simulated annealing
- Unigram vs trigram scoring
- High or low initial temperature (for simulated annealing)
- Uniform vs Gaussian swaps
- Random or guided initial alphabet
As we're trying to find out if simulated annealing is better than hillclimbing, I'll look at the other four parameters and compare simulated annealing and hillclimbing in each situation.
Both hillclimbing and simulated annealing are stochastic methods (they use randomness in the algorithm). That means that different runs are likely to produce different results. Therefore, I run the algorithm with ten workers in each situation, each working independently. The algorithm will return the best fitness of all the workers, but I show graphs of the scores of each worker.
I use the same ciphertext for all experiments.
Results
Unigram scoring
The first combination to look at will give us a baseline we can use to compare the performance of the other algorithm/parameter combinations. The simplest thing we can do is give the algorithms a random starting key, uniformly select swaps, and use unigram scoring for measuring fitness.




The results show that hillclimbing (on the left) quickly finds one solution and sticks with it: the fitness score doesn't deviate much. But looking at the τ score shows that it rejects slightly better keys as they yield lower fitness scores. The simulated annealing traces (on the right) show that the algorithm doesn't stabilise on a single solution until the end of the run, but the variation reduces over time; that's what we'd expect as the temperature drops from high to low.
But even though all runs of both algorithms eventually find similar solutions (same fitness score, very similar τ scores), the low τ score shows that this is a poor solution.
It seems that unigram scoring is not the way to go.
Trigram scoring
What if we repeat the previous experiment, but use trigram scoring?




The first thing to note is that both algorithms do well. We can see that from the τ scores: both algorithms end with most or all of the runs ending at a τ score of 1.0, showing that they've found the correct key. However, every simulated annealing worker finds the correct key, while only about half the hillclimbing workers find it. This suggests that simulated annealing is more likely to find the best solution.
Another interesting feature is the time scale of finding the solution. Hillclimbing has essentially stabilised by 2500 iterations: only one of the workers progresses after this point. Simulated annealing, on the other hand, shows an increase in fitness throughout the run. But a look at the τ plot shows that it's only the last 8000 or so iterations where the correct key is being found. It seems likely that the annealing temperature before this is too high for any potential solution to survive.
Guessing the key
Before I look at the temperature to use with simulated annealing, I'll do another comparison between hillclimbing and simulated annealing. Does the initial guess of the key make any difference?
The experiments above used a random initial key, but we could seed the algorithm with our best guess of the key, based on unigram letter frequencies. This is quick and easy to compute, and is likely to be somewhat close to the final solution.




If we compare these graphs to the ones above, we see that the initial fitness and τ scores are higher than with a random alphabet. With hillclimbing, these scores increase. But the simulated annealing traces show that the initial boost in fitness and τ is soon erased by the algorithm choosing worse solutions in order to explore more of the solution space.
However, it should come as no surprise that both algorithms find the correct solution.
Limiting swaps
If we're giving the algorithm a mostly-correct initial key, we would expect that the best changes would be to swap nearby letters in the key, as these are more likely to be better; swaps between letters in very different parts of the key is likely to be harmful.
(This makes sense if we keep the mapping in order of highest to lowest frequency of letter, so rather than a mapping that looks like this:
| Plaintext alphabet | a | b | c | d | ... |
|---|---|---|---|---|---|
| Ciphertext alphabet | q | m | g | c | ... |
, with the plaintext alphabet in alphabetical order, we have a mapping that looks like this:
| Plaintext alphabet | e | t | o | a | ... |
|---|---|---|---|---|---|
| Ciphertext alphabet | t | f | b | q | ... |
, where the plaintext alphabet is in order of frequency of that letter in normal English.)




As you can see, it makes very little difference. The hillclimbing results are just about identical with the previous runs. With simulated annealing, the fitness score seems to be slightly higher between 1000 and 8000 iterations, but there's basically nothing in it.
Simulated annealing temperature
The final parameter to vary is the initial temperature of the simulated annealing algorithm. It's clear from the experiments above that the simulated annealing effectively scrambles the initial key and doesn't begin to stabilise on a good solution until about the last 7000 iterations. Perhaps a lower starting temperature would work better?


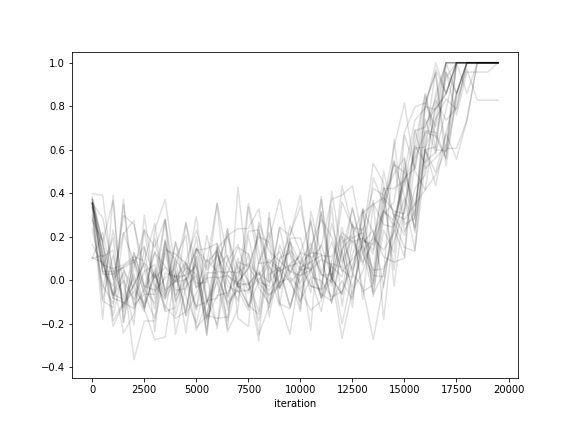

This shows that the initial reasonable guess at the key is preserved: the top right graph shows that the trigram fitness only increases from the initial score of around -8500, and the bottom right graph shows that the τ score is consistently higher when the temperature starts lower. It's also clear that the lower-temperature run settles to a nearly-optimal solution earlier.
That's what happens when the simulated annealing is given a good guess at the initial key. What happens if we go back to an earlier condition and give it a random initial key (using uniformly-selected letter swaps)?




The results on the left are familiar from above. Compared to them, it's clear that the lower temperature run quickly moves towards a cipher key that's about as good as the letter-frequency inspired best-guess and then the run continues similarly to the other low-temperature run.
Conclusions
The main takeaway from these experiments is that monoalphabetic substitution ciphers are easy to break. Even a straightforward hillclimbing algorithm, combined with trigram scoring to evaluate possible breaks, is capable of breaking these ciphers, given about 2000 characters of ciphertext.
Simulated annealing does slightly better, but only in the sense that an individual worker is more likely to find the correct solution while using simulated annealing than hillclimbing. But this advantage is eliminated when using several workers and picking the best result from the pool.
There are several parameters to vary with these algorithms: the initial guess at the key, how swaps are performed to change the key, the starting temperature of the simulated annealing, and so on. What these experiments show is that these parameters don't really affect the overall outcome: monoalphabetic substitution ciphers are easy to break, however you decide to do it.
Code
The code for these experiments is on Github, in the hillclimbing-results directory.
Credits
Cover photo by Nick Karvounis