Day 18 was a complicated beast, made a bit more complicated than it need be by the incursion of Christmas celebrations in the time it took me to complete it!
It's also a complicated task, with lots of thinking involved in solving it, so this post is longer than most.
Data structures, 1
The first decision was how to represent the cave. I started by taking a direct approach: the cave was a Set of Positions; the locations of keys and doors were represented as a Map from the position to the label of the key or door; and I used a CaveComplex record to contain the layout of the cave and the positions of the keys and doors.
type Position = (Integer, Integer) -- r, c
type PointOfInterest = M.Map Position Char
type Cave = S.Set Position
data CaveComplex = CaveComplex { _cave :: Cave
, _keys :: PointOfInterest
, _doors :: PointOfInterest
} deriving (Eq, Ord, Show)
type CaveContext = Reader CaveComplex
Building the cave complex was relatively straightforward. Starting with an empty CaveComplex, I fold over each row in the text file, updating the CaveComplex as I go. Similarly, each row is processed as a fold over the characters in the row.
buildCaveCell has the logic of how to interpret each character in the map, making sure to include doors, keys, and the explorer as possible spaces in the cave.
buildCaveComplex text = foldl' buildCaveRow (cc0, explorer0) $ zip [0..] rows
where cc0 = CaveComplex {_cave = S.empty, _keys = M.empty, _doors = M.empty}
explorer0 = emptyExplorer -- Explorer { _position = (0, 0), _keysHeld = S.empty }
rows = lines text
buildCaveRow (cc, explorer) (r, row) = foldl' (buildCaveCell r) (cc, explorer) $ zip [0..] row
buildCaveCell r (cc, explorer) (c, char)
| char == '.' = (cc', explorer)
| char == '@' = (cc', explorer { _position1 = here })
| isLower char = (cc' { _keys = M.insert here char $ _keys cc'}, explorer)
| isUpper char = (cc' { _doors = M.insert here char $ _doors cc'}, explorer)
| otherwise = (cc, explorer)
where cc' = cc { _cave = S.insert here $ _cave cc }
here = (r, c)
Part 1
I started by using a standard A* search to find the solution. To simplify the code, I used a Reader monad to contain the state of the cave complex, to avoid passing it around as a parameter throughout the various parts of the code. (Things changed a lot for part 2, so here is the code for part 1.)
The search revolves around an agenda of partial results to search from. Each partial result contains the position of the explorer and the keys its picked up so far. The agenda is stored as a priority queue, ordered so that the smallest predicted cost of completing the task is the first agendum in the queue.
Here's the core of the search algorithm. The closed set contains explorer states that have already been processed: if the search visits these states again, they're not added to the agenda.
aStar :: Agenda -> ExploredStates -> CaveContext (Maybe Agendum)
aStar agenda closed
| P.null agenda = return Nothing
| otherwise =
do let (_, currentAgendum) = P.findMin agenda
let reached = _current currentAgendum
nexts <- candidates currentAgendum closed
let newAgenda = foldl' (\q a -> P.insert (_cost a) a q) (P.deleteMin agenda) nexts
reachedGoal <- isGoal reached
if reachedGoal
then return (Just currentAgendum)
else if reached `S.member` closed
then aStar (P.deleteMin agenda) closed
else aStar newAgenda (S.insert reached closed)
These are the extra data structures it needs.
data Explorer = Explorer { _position :: Position
, _keysHeld :: Keys
} deriving (Eq, Ord, Show)
type ExploredStates = S.Set Explorer
data Agendum = Agendum { _current :: Explorer
, _trail :: Q.Seq Explorer
, _cost :: Int} deriving (Show, Eq)
type Agenda = P.MinPQueue Int Agendum
The candidates are the new explorer states to consider. The nonloops check is mainly to prevent the search stepping back to where it just came from, but it can catch other duplicate candidates too. Note that the important check of the closed set occurs in the main aStar function. successors is the main domain-dependent function here. It finds the cave locations adjacent to the current position, checks that the explorer has the right key for any doors, and picks up any keys at the current location.
candidates :: Agendum -> ExploredStates -> CaveContext (Q.Seq Agendum)
candidates agendum closed =
do let candidate = _current agendum
let previous = _trail agendum
succs <- successors candidate
let nonloops = Q.filter (\s -> not $ s `S.member` closed) succs
mapM (makeAgendum candidate previous) nonloops
makeAgendum :: Explorer -> (Q.Seq Explorer) -> Explorer -> CaveContext Agendum
makeAgendum candidate previous new =
do cost <- estimateCost new
return Agendum { _current = new
, _trail = candidate <| previous
, _cost = cost + (Q.length previous)
}
successors :: Explorer -> CaveContext (Q.Seq Explorer)
successors explorer =
do let here = _position explorer
let locations0 = possibleNeighbours here
cave <- asks _cave
keys <- asks _keys
doors <- asks _doors
let keysHeld = _keysHeld explorer
let locations1 = Q.filter (`S.member` cave) locations0
let locations2 = Q.filter (hasKeyFor doors keysHeld) locations1
return $ fmap (\l -> explorer { _position = l, _keysHeld = pickupKey keys keysHeld l}) locations2
possibleNeighbours :: Position -> Q.Seq Position
possibleNeighbours (r, c) = [(r + 1, c), (r - 1, c), (r, c + 1), (r, c - 1)]
Finally, the search is guided by the estimatedCost heuristic. This provides an estimate of the remaining work to be done in finding a solution. In order to ensure the algorithm is optimal, the heuristic has be to admissible: it cannot result in an overestimate of the amount of work remaining.
My first attempt at a heuristic was to sum the manhattan distances to all remaining keys. However, this wasn't admissible as it would often overestimate the work needed. If there were two keys along the same tunnel in the maze, the work to pick up both keys would be the same as the work to pick up just the furthest one (the explorer would pick up the nearest one on the way). This wrong heuristic led to some wrong answers for the sample problems!
A better heuristic was to find the maximum and minimum values for the row and column of the unfound keys, and then estimate the distance from the explorer to these rows and columns.
estimateCost :: Explorer -> CaveContext Int
estimateCost explorer = -- return 0
do keys <- asks _keys
let (r, c) = _position explorer
let unfoundKeys = M.filter (`S.notMember` (_keysHeld explorer)) keys
let minR = minimum $ map fst $ M.keys unfoundKeys
let minC = minimum $ map snd $ M.keys unfoundKeys
let maxR = maximum $ map fst $ M.keys unfoundKeys
let maxC = maximum $ map snd $ M.keys unfoundKeys
let spanR = spanV r minR maxR
let spanC = spanV c minC maxC
if M.null unfoundKeys
then return 0
else return $ fromIntegral (spanR + spanC)
spanV this minV maxV
| this < minV = maxV - this
| this > maxV = this - minV
| otherwise = (this - minV) + (maxV - this)
This all worked fine, and got the right solution. But it managed to do it rather slowly.
Thinking about Part 2
Unfortunately, this direct approach didn't work for part 2, where there are four explorers moving around the cavern. The key reason for this lies in something termed the branching factor of the search.
Each state on the path to the solution is determined by the positions of each of the four explorers, and the set of all the keys collected between them. The solution to part 2 requires just over 2000 steps. For each of those steps, the search algorithm has to consider up to three successor positions, and do so for each of the four explorers. That means that each state in the search tree can have up to twelve successors that need exploring. The number of successors of each state is termed the branching factor.
Let's say that the average number of successor nodes for each explorer is n, and that there are d steps in the solution. That means there are 4n successors of the first state, 4n × 4n successors after two steps, 4n× 4n × 4n successors after three states, and eventually (4n)d = 4d×nd states after all d steps have been explored.
Most of the time, there's only one successor for each explorer, as the explorer is moving down a corridor. That means that n is small, say about 1.1 or 1.2. But even so, the fact that there are four explorers makes the size of the search space explode.
The cause of the problem is that we need to track the separate movement of each explorer, even if they're essentially independent. Consider the simple example cavern below, with two explorers. We don't really care which explorer moves first or second, so long as the leftmost explorer ends up one the a key, opening the door for the rightmost explorer.
#######################
#.B.a...@..#..@...A.b.#
#######################
There are a couple of ways of solving this problem. One is to drop the constraint on looking at all orderings of explorer movement. The other is somehow to shorten the path length.
Dropping the constraint on ordering is commonly seen in partial-order planning systems. The idea is to record both the steps taken by each explorer, and the constraints between which steps can be taken when. In this case, that's the constraints on when keys have been collected, allowing doors to be opened. That would allow me to construct the plan for each explorer separately, and then combine those separate plans into one plan overall. For this problem, there are no real interactions between the different explorers (the different explorers are held separate from each other) and the total length of the path is just the sum of the lengths of the separate plans for each explorer.
But I wanted a solution that was more generally true. The partial-order search idea would require a lot of work to sort out the general case of how to constrain the interleaving of the steps in the separate plans. It could also be the case that one explorer needs to take the long way round to get a key early, allowing other explorer to follow much shorter routes, meaning that combining the sub-plans would need to take account of these possible interactions. That left the other choice, that of shortening the path length of the solution.
The important part of the "length" is the number of choices made by the search algorithm, not the number of steps taken by the explorer. Most of the time, the explorer is constrained to move along a corridor. I can contract the map of the cavern into a graph that is just the keys and how they are connected. This will reduce the map from being one that contains over 3000 possible steps to one that contains just 75 connections.
Contracting the map
First, I need to define some data structures to hold the contracted cavern. A CaveEdge holds everything important to remember about moving around the cavern: the keys connected by this edge, the keys required to move along this edge, and the distance travelled by the robot.
type Connection = (Char, Char)
data CaveEdge = CaveEdge { _connections :: Connection
, _keysRequired :: S.Set Char
, _distance :: Int
} deriving (Eq, Ord, Show)
makeLenses ''CaveEdge
type Cave = S.Set CaveEdge
I also renamed the CaveComplex to ExpandedCaveComplex; a CaveComplex is now the container for the contracted version.
Contracting the cave is a breadth-first search from each key (and robot starting position) outwards. contractCave creates the whole graph with a fold. contractFrom finds all the edges that start at a particular key (or starting position). reachableFrom does the breadth-first search, using a boundary list of positions to explore.
The four alternative clauses in reachableFrom handle the four cases.
- If the current position has already been processed (and is in the
closedset), drop the position and carry on. - If the current position is a key, record the new edge in the cave and continue searching the rest of the boundary.
- If the current position is a door, record that this key is needed for wherever this edge ends up, then continue as case 4.
- Otherwise, find the neighbours of the position, add them to the boundary, and move on.
contractCave :: ExpandedCaveComplex -> [Position] -> CaveComplex
contractCave expanded startPositions = cavern
where explorers = M.fromList $ zip startPositions $ map intToDigit [0..]
starts = M.union explorers (expanded ^. keysE)
cavern0 = CaveComplex {_cave = S.empty, _keys = S.fromList $ M.elems (expanded ^. keysE)}
cavern = M.foldrWithKey (contractFrom expanded) cavern0 starts
contractFrom :: ExpandedCaveComplex -> Position -> Char -> CaveComplex -> CaveComplex
contractFrom expanded startPos startKey cc = cc { _cave = S.union (_cave cc) reachables }
where reachables = reachableFrom [(startPos, edge0)] S.empty expanded' startKey
edge0 = CaveEdge {_connections = ('0', '0'), _keysRequired = S.empty, _distance = 0}
expanded' = expanded & keysE %~ (M.delete startPos)
reachableFrom :: [(Position, CaveEdge)] -> (S.Set Position) -> ExpandedCaveComplex -> Char -> Cave
reachableFrom [] _closed _expanded _startKey = S.empty
reachableFrom ((here, edge):boundary) closed expanded startKey
| here `S.member` closed = reachableFrom boundary closed expanded startKey
| here `M.member` ks = S.insert edgeK $ reachableFrom boundary closed' expanded startKey
| here `M.member` drs = reachableFrom boundaryD closed' expanded startKey
| otherwise = reachableFrom boundary' closed' expanded startKey
where nbrs0 = S.intersection (expanded ^. caveE) $ possibleNeighbours here
nbrs = S.difference nbrs0 closed
closed' = S.insert here closed
ks = expanded ^. keysE
drs = expanded ^. doors
edge' = edge & distance %~ (+1)
edgeK = edge & connections .~ (mkConnection startKey (ks!here))
edgeD = edge' & keysRequired %~ (S.insert (toLower (drs!here)))
neighbours = S.map (\n -> (n, edge')) nbrs
neighboursD = S.map (\n -> (n, edgeD)) nbrs
boundary' = boundary ++ (S.toAscList neighbours)
boundaryD = boundary ++ (S.toAscList neighboursD)
This uses a couple of utility functions for handling when edges touch each other.
mkConnection :: Char -> Char -> Connection
mkConnection a b = if a < b then (a, b) else (b, a)
edgeTouches :: Char -> CaveEdge -> Bool
edgeTouches x e
| x == a = True
| x == b = True
| otherwise = False
where (a, b) = e ^. connections
anyEdgeTouch :: Keys -> CaveEdge -> Bool
anyEdgeTouch xs e = S.foldl' (\t x -> t || (edgeTouches x e)) False xs
edgeOther :: Char -> CaveEdge -> Char
edgeOther x e
| x == a = b
| otherwise = a
where (a, b) = e ^. connections
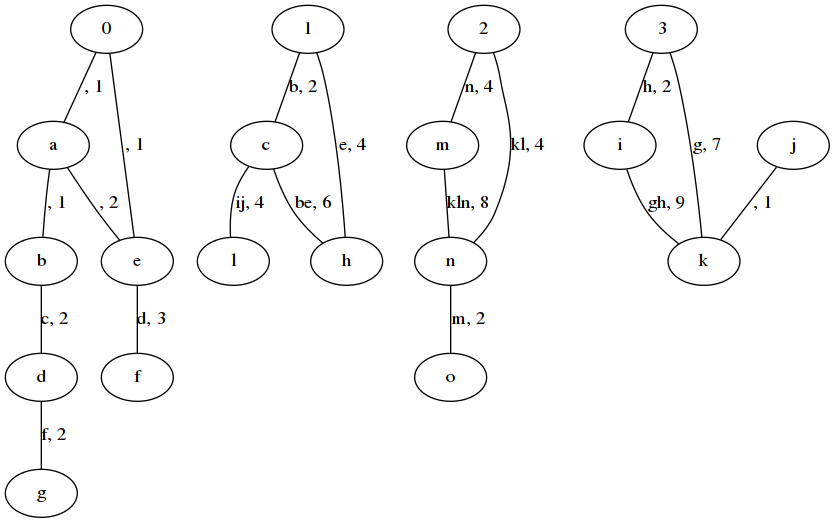
Contraction results in much smaller representations of the cave. This example cave:
#############
#g#f.D#..h#l#
#F###e#E###.#
#dCba@#@BcIJ#
#############
#nK.L@#@G...#
#M###N#H###.#
#o#m..#i#jk.#
#############
becomes this graph of keys. Each node is a point of interest (a key or a starting position, represented by numbers). The label of each edge is the keys required to move along the edge, and the distance travelled.
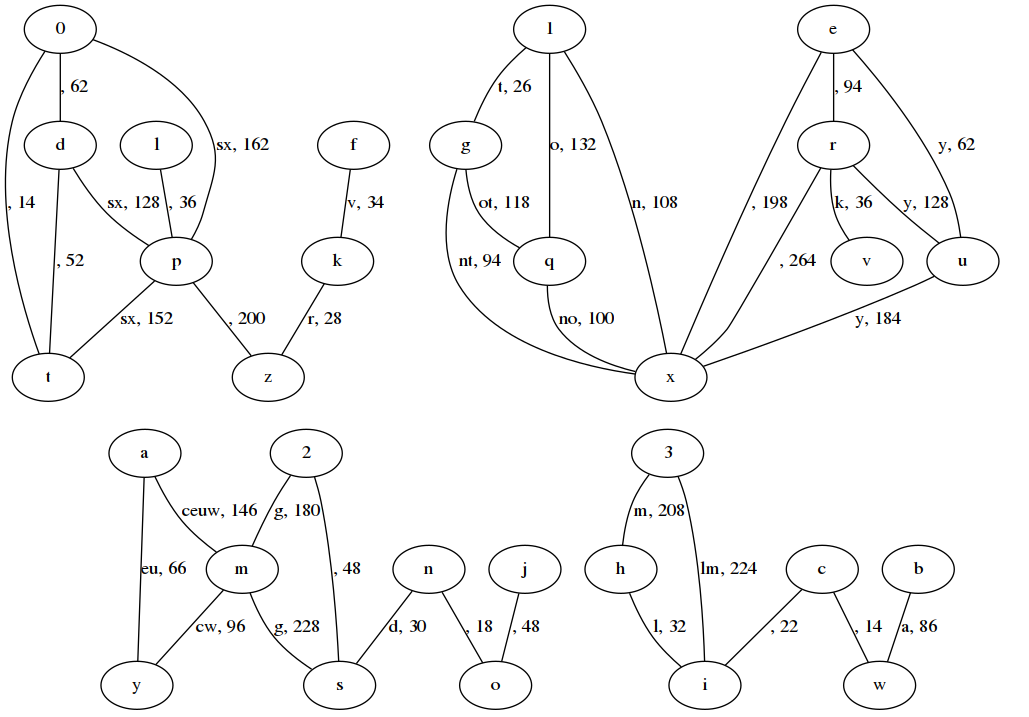
The contraction of the full problem is much more dramatic, with journeys of over 200 steps being compressed to a single edge in the graph.
Solving part 2
Now I have a simpler representation of the problem, solving it becomes practical. The definition of Explorer has to change, as I need to track a Set of robots rather than just one. It also tracks the total distance travelled by all robots, rather than recalculating it from the set of edges used.
data Explorer = Explorer { _position :: S.Set Char
, _keysHeld :: Keys
, _travelled :: Int
} deriving (Show)
makeLenses ''Explorer
instance Eq Explorer where
e1 == e2 = (_position e1 == _position e2) && (_keysHeld e1 == _keysHeld e2)
instance Ord Explorer where
e1 `compare` e2 =
if _position e1 == _position e2
then (_keysHeld e1) `compare` (_keysHeld e2)
else (_position e1) `compare` (_position e2)
After a digression into typeclasses, I adjusted the code for part 1 to use the same Explorer data structure, just using a Set of one robot rather than a Set of four.
Much of the A* search algorithm is the same. The successors function changes to deal with the new CaveComplex data structure
successors :: Explorer -> CaveContext (Q.Seq Explorer)
successors explorer =
do let heres = explorer ^. position
cavern <- asks _cave
let kH = explorer ^. keysHeld
let locations0 = S.filter (\e -> anyEdgeTouch heres e) cavern
let locations1 = S.filter (\e -> S.null ((e ^. keysRequired) `S.difference` kH)) locations0
let succs = S.foldr' (\e q -> (extendExplorer explorer e) <| q) Q.empty locations1
return succs
extendExplorer :: Explorer -> CaveEdge -> Explorer
extendExplorer explorer edge =
explorer & position .~ pos'
& keysHeld .~ kH'
& travelled .~ d'
where here = S.findMin $ S.filter (\p -> edgeTouches p edge) (explorer ^. position)
there = edgeOther here edge
kH' = S.insert there (explorer ^. keysHeld)
d' = (explorer ^. travelled) + (edge ^. distance)
pos' = S.insert there $ S.delete here (explorer ^. position)
The cost estimation function also changes. I now use the furthest distance of any unfound key from any explorer robot, plus 1 for each other unfound key.
estimateCost :: Explorer -> CaveContext Int
estimateCost explorer = -- return 0
do let heres = explorer ^. position
ks <- asks _keys
cavern <- asks _cave
let kH = explorer ^. keysHeld
let unfound = ks `S.difference` kH
let unfoundEdges0 = S.filter (\e -> anyEdgeTouch heres e) cavern
let unfoundEdges = S.filter (\e -> not $ anyEdgeTouch kH e) unfoundEdges0
let furthest = S.findMax $ S.insert 0 $ S.map _distance unfoundEdges
return $ max 0 $ furthest + (S.size unfound) - 1
Performance
Unfortunately, this still takes quite a while to run. Profiling it suggests that about 50% of the time is spent in the compare function for Explorer and about 10% is in anyEdgeTouch.
The Ord instance for Explorer started looking like this:
instance Ord Explorer where
e1 `compare` e2 =
if _position e1 == _position e2
then (_keysHeld e1) `compare` (_keysHeld e2)
else (_position e1) `compare` (_position e2)
I tried a couple of variations on this, and it make little difference. The only thing I discovered is that things go wrong if the Ord instance and Eq instance give different answers for when Explorers are equal!
But I did pick up one neat trick, using the fact that Ord is and instance of Monoid, so the instance can be more succinctly expressed like this.
instance Ord Explorer where
e1 `compare` e2 =
((_position e1) `compare` (_position e2))
<> ((_keysHeld e1) `compare` (_keysHeld e2))
Lenses
I used lenses a bit more in this program, after my first forays. I think they're a bit neater, and perhaps clearer once you've got your eye in. Compare this update (with lenses)
(cc' & keysE %~ (M.insert here char), startPosition)
with this one (without lenses)
(cc' { _keysE = M.insert here char $ _keysE cc'}, startPosition)
Similarly, the use of a function in the over lens action makes the "increment" action clearer in this case.
edge' = edge & distance %~ (+1)
As before, I'm not using deeply nested structures, so the difference between using lenses and not isn't as large as it could be.
Code
You can see the code as at the end of part 1, and the final code (and final code on Github).