Another year, another Advent of Code done, another review of how it went.
As alway, huge thanks to Eric Wastl and the team for putting together another successful event. The puzzles were entertaining, the delivery was flawless, and the Reddit community around the event was expertly moderated. Well done everyone for putting on a great event. (You can see my previous reviews on 2020, 2021, and 2022).
The puzzles
Again, the puzzles are good, engaging, with clear descriptions. They're not too small to be trivial and big to be overwhelming; saying that, the early puzzles are typically small and the later ones are large.
I think the difficulty of the first few puzzles this year was a bit unexpected. I put that down to day 2 and 3 falling on a weekend, when the AoC team tend to pose more complex puzzles on the basis that people have more time.
Generally, the puzzles were ones of programming and computing, where the challenge was to choose the right data structures and algorithms to solve the problem, often by working out how to address problem instances too large to tackle by brute force. The test cases and examples in the problem descriptions were generally great, with only a couple of cases where examples missed some important part of the problem. There were a few cases where early problems laid groundwork for later problems (day 5 preparing for day 19; day 8 preparing for day 20; day 10 preparing for day 18).
There were quite a few days where having the correct representation for a problem helped enormously when finding a solution, especially when that representation allowed me to declaratively state some facts about the solution. Days 3, 5, 7, 13, and 17 are good examples of this.
Use of AI/Copilot
One difference this year was the use of large language models (LLMs) to support programming. I used the Copilot feature in VS Code, with mixed success. It was useful at filling out multiple cases in pattern matching, or writing little snippets of straightforward code. But for anything beyond those simple uses, I found the LLM to be dangerous. It would suggest something for the code to write, but it was rarely what I wanted but often looked plausible.
Programming concepts and language features
The Advent of Code site says that
You don't need a computer science background to participate - just a little programming knowledge and some problem solving skills will get you pretty far.
That's true, and perhaps more true in this year than previous years. There was very little esoteric programming knowledge needed for solving these tasks. One particular algorithm (the Shoelace algorithm) was needed for a couple of tasks, but that was easy to find with a quick search online. Dynamic programming was used once, and there were several examples of graph search; but both of those are reasonably fundamental algorithms. The most complex data structures I used were maps, sets, and arrays.
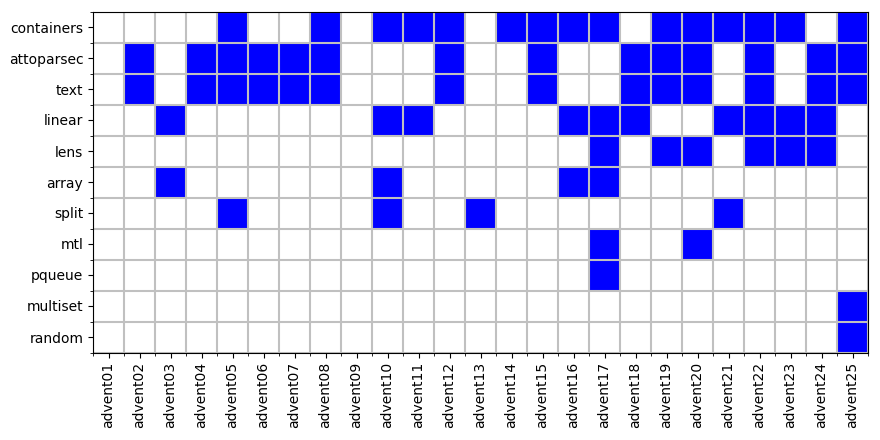
That is borne out in the packages and modules I used this year. (In Haskell terms, a module is a library imported into a program; they're typically small and focused. A package is a bundle of modules that tend to work together, grouped into one downloadable item.) From the table below, you can see that I use only a few packages. containers provides Map, Set, and Sequence; attoparsec and text are used for parsing input; linear is used for coordinates (and there are a lot of coordinate-based problems this year!). mtl provides Reader and State monads, and you can see that's only used twice.
Package |
Num. uses |
|---|---|
| containers | 15 |
| attoparsec | 14 |
| text | 14 |
| linear | 10 |
| lens | 6 |
| array | 4 |
| split | 4 |
| mtl | 2 |
| multiset | 1 |
| pqueue | 1 |
| random | 1 |
Looking at the packages used for each day shows that the later days tended to use more packages, but those were more complex problems.
Haskell features
A few bits of Haskell the language made my life easier. Most important was the strong typing system. This saved me from all sorts of silly mistakes, from calling functions with arguments in the wrong order to missing steps from the algorithm I used. I sometimes used the types to guide what I wrote: I knew what types I had and what types I wanted, and the conversion from one to the other was reasonably mechanical.
I exploited laziness quite a lot too, most obviously when I had to detect loops in states; creating an infinite stream of states, then testing it for properties, is easier to write than interleaving the creation and testing stages.
The other great feature is the use of parser combinators to read and process input files. They're still wonderful to use, and it's great to see them appear in other languages like Rust's nom library.
Of the more "esoteric" Haskell features, I used monoids a couple of times to handle "combining" objects, including one time where I used the Endo monoid to represent functions as objects so I could easily do repeated application. I used typeclasses a couple of times to handle polymorphism, including once with phantom types. I used GHC's patterns a lot with the Sequence library, and once to define my own patterns to simplify some repetitive code. I only used monads a few times, and the State monad only once.
But apart from that, I didn't need to use anything really obscure, I think. No type level programming, no heavy use of defining my own Applicative or Monad classes. That's a testament to accessibility of the puzzles in Advent of Code.
Terseness
Haskell is a pretty terse language, and that's reflected in the amount of code I wrote. I have a standard library function to load data files, but that's only about six lines. Note that these counts include blank lines, comments, type definitions, and type declarations on functions.
| Program | Lines of code |
|---|---|
| advent01 | 40 |
| advent02 | 110 |
| advent03 | 104 |
| advent04 | 75 |
| advent05 | 148 |
| advent06 | 42 |
| advent07 | 110 |
| advent08 | 119 |
| advent09 | 47 |
| advent10 | 180 |
| advent11 | 80 |
| advent12 | 92 |
| advent13 | 71 |
| advent14 | 76 |
| advent15 | 78 |
| advent16 | 99 |
| advent17 | 193 |
| advent18 | 92 |
| advent19 | 252 |
| advent20 | 197 |
| advent21 | 121 |
| advent22 | 140 |
| advent23 | 139 |
| advent24 | 128 |
| advent25 | 103 |
That's a median size of 104 lines.

Performance
Another claim made by Advent of Code is that
[E]very problem has a solution that completes in at most 15 seconds on ten-year-old hardware.
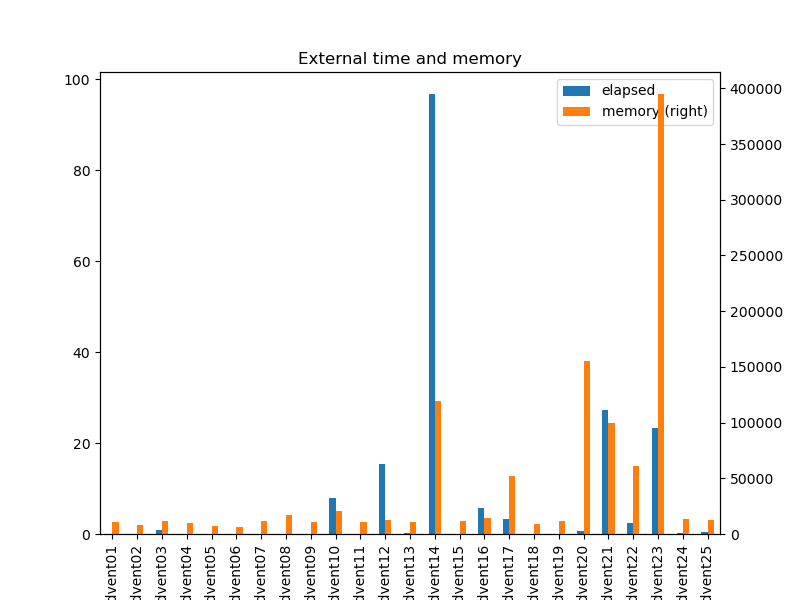
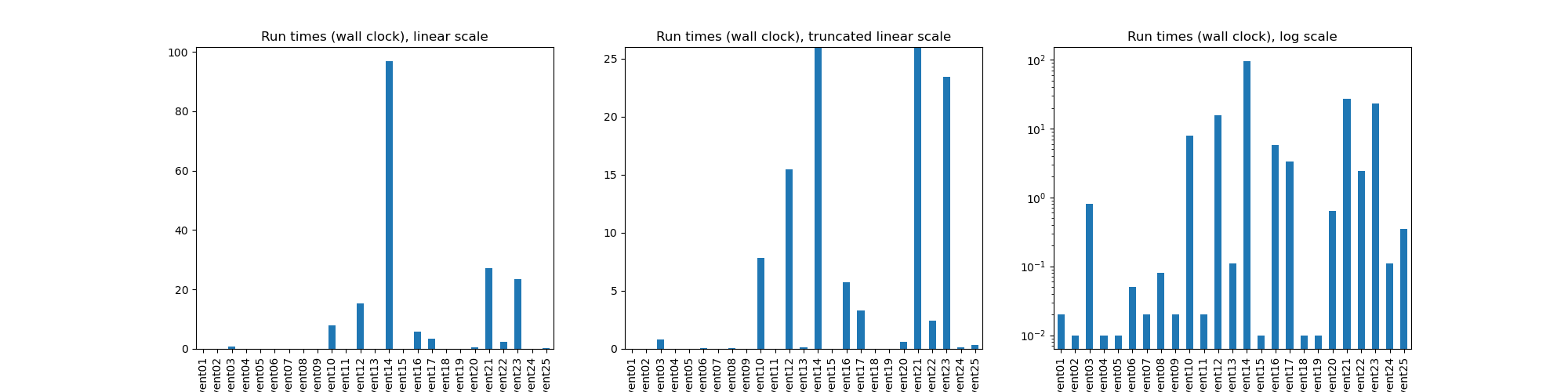
That was mostly true for my non-optimised solutions. Most solutions run in under a second, one takes 15 seconds, two take about 25 seconds, and one takes a minute and a half (see the chart below, on both linear and logarithmic scales).
If you want the numbers, here they are:
| Program | Time (s) | Memory used (kb) |
|---|---|---|
| advent01 | 0.02 | 11044 |
| advent02 | 0.01 | 7964 |
| advent03 | 0.81 | 11636 |
| advent04 | 0.01 | 9480 |
| advent05 | 0.01 | 7224 |
| advent06 | 0.05 | 6600 |
| advent07 | 0.02 | 11744 |
| advent08 | 0.08 | 16688 |
| advent09 | 0.02 | 10436 |
| advent10 | 7.83 | 20564 |
| advent11 | 0.02 | 10844 |
| advent12 | 15.44 | 12604 |
| advent13 | 0.11 | 11128 |
| advent14 | 96.78 | 119800 |
| advent15 | 0.01 | 11472 |
| advent16 | 5.74 | 14480 |
| advent17 | 3.34 | 52012 |
| advent18 | 0.01 | 9232 |
| advent19 | 0.01 | 11868 |
| advent20 | 0.63 | 155440 |
| advent21 | 27.18 | 99264 |
| advent22 | 2.45 | 60956 |
| advent23 | 23.42 | 394916 |
| advent24 | 0.11 | 13724 |
| advent25 | 0.35 | 12864 |
Memory use was generally low, about a Mb or so. Day 23 used a lot, but that was probably it storing lots of potentially longest paths. Day 20 also uses a lot of memory, probably due to it storing the cache of all previously-seen states.

The only optimisation I did was to ensure the solutions would run in less than a couple of hours, by picking the correct algorithms. In particular, day 14 uses a very slow list-of-lists representation that I iterate over multiple time for each step in the algorithm. I'll see how to optimise the slow solutions and post some updates for them.
Code
You can get the code from my locally-hosted Git repo, or from Gitlab.