
Another Advent of Code is over, so it's time to review how it went for me.
The first thing is to thank Eric Wastl and his team for another excellent event and set of challenges. I always look forward to these events, both because of the challenge of the puzzles themselves, and because it's the one time I year I can get to program in Haskell. I think that over time, I'm becoming more familiar with Haskell and the tools provided by the language's ecosystem, so my solutions are making better use of existing features and less reinventing wheels.
(You may like to compare this review with the review of 2021 and review of 2020.)
The puzzles
My day job is a computing senior lecturer (vaguely equivalent to "associate professor" for our American colleagues), which means I have high standards and a critical eye when it comes to describing tasks for others.
These puzzles are great!
The tasks descriptions are very clear, with excellent examples. For every puzzle this year, I tested my code against the supplied example. There were only one or two places where my code worked correctly on the example input and not on the real input.
My only one niggle was with day 20, where the example didn't have a case where the offset was larger than the size of the list being rotated.
Programming concepts
The Advent of Code site claims that
You don't need a computer science background to participate - just a little programming knowledge and some problem solving skills will get you pretty far.
I think that's true. Most of the puzzles involved simple programming concepts, such as some basic data structures and some fundamental algorithms. Graph search was a prominent motif this year, along with decisions about how to represent a seemingly-unrelated task to a graph of states that can be searched.
Another concept was the evaluation of a structure, such as collapsing a set of operations into a summary value, as we saw with the shouting monkeys in day 21. What I don't think we've seen so far is where the same structure is evaluated in different ways, akin to applying a different algebra to the same structure and interpreting it differently. (I don't count day 2's rock-paper-scissors, as that has the same text parsed in different ways.)
Generally, most of the problems required a bit of thought and then a little bit of programming. There were few edge cases to deal with, and no input validation. That made the solutions generally short.
A few concepts that were out of the ordinary were:
- Zippers for moving around a tree by relative positions
- Representing regions as functions
- Treating functions as a monoid to allow them to be combined
- Circular lists, with a zipper-like interface
Haskell the language
Haskell is a terse language. The solutions are generally short, mostly around 100 lines of code (including imports and the like) The median is 97 lines of code. Note that programs 12, 16, 19, and 24 reused a standard implementation of A* that takes about 100 lines.
| Program name | Lines of code |
|---|---|
| advent01 | 22 |
| advent02 | 93 |
| advent03 | 51 |
| advent04 | 57 |
| advent05 | 105 |
| advent06 | 30 |
| advent07 | 137 |
| advent08 | 76 |
| advent09 | 97 |
| advent10 | 76 |
| advent11 | 148 |
| advent12* | 155 |
| advent13 | 61 |
| advent14 | 107 |
| advent15 | 91 |
| advent16* | 274 |
| advent17 | 171 |
| advent18 | 72 |
| advent19* | 221 |
| advent20 | 56 |
| advent21 | 118 |
| advent22 | 269 |
| advent23 | 215 |
| advent24* | 224 |
| advent25 | 52 |

In addition, the declarative and functional basis of Haskell meant that I could express many problems very clearly. I could concentrate on what the problem was, rather than getting bogged down in the detail of how to find a solution. For example, for Day 4 I just wrote down some facts about interval relations and that was enough to express the solution. Laziness and infinite streams helped express several problems concisely, such as the cycle-finding in day 17 that made heavy use of infinite simulations which I then filtered to find the interesting elements.
Haskell's typeclass feature came in handy a couple of times. It allowed me to reuse almost all the code for the two parts of day 16, and a custom definition of the Ord typeclass made day 13 almost trivially easy.
Performance
The Advent of Code site states that
every problem has a solution that completes in at most 15 seconds on ten-year-old hardware.
I failed here, with four of my solutions taking over a minute to execute, and one taking nearly 20 minutes! Expect some posts in the near future on optimising these programs and reducing the execution times. (Update: now done! See below.) I was disappointed that many solutions took as along as they did, but I didn't do any particular optimisation on any of them. Instead, I chose (what was to me) the obvious approach to each problem and was happy if it worked.

Memory use was another surprise. All bar two of the programs ran in small amounts of memory, around a megabyte or so. The two that ran longer were the beast what was day 19, and a surprising amount of memory usage for day 15. That is likely to be the allocation of about four million points to explore for beacons, and is a case where some laziness in the program could have led to a better solution.

Another perspective on memory use is the number of memory allocations made. Many of these are short-lived and reclaimed by the garbage collector. As you can see, in most cases the memory churn follows the memory use.
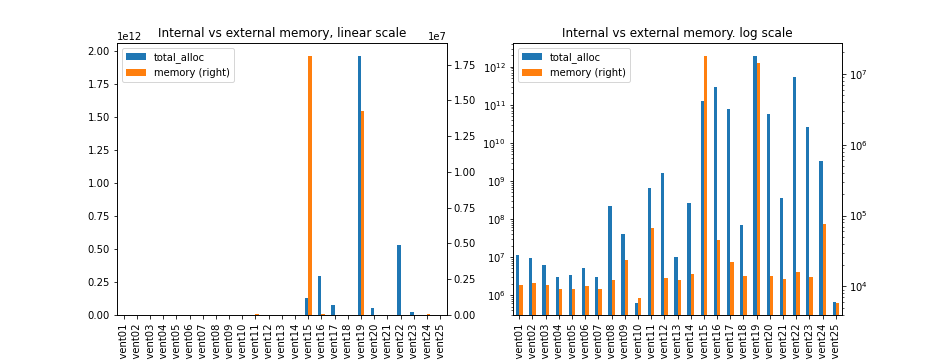
If you want the numbers for time and memory use, here's the table.
| Program | Elapsed time (s) | Max memory (kb) |
|---|---|---|
| advent01 | 0.02 | 10,488 |
| advent02 | 0.02 | 11,112 |
| advent03 | 0.02 | 10,408 |
| advent04 | 0.01 | 9,040 |
| advent05 | 0.01 | 9,324 |
| advent06 | 0.02 | 10,124 |
| advent07 | 0.01 | 9,192 |
| advent08 | 0.09 | 12,204 |
| advent09 | 0.06 | 23,660 |
| advent10 | 0.01 | 6,800 |
| advent11 | 0.36 | 66,664 |
| advent12 | 1.09 | 13,264 |
| advent13 | 0.01 | 12,300 |
| advent14 | 0.85 | 15,068 |
| advent15 | 2:17.27 | 18,101,260 |
| advent16 | 2:24.64 | 45,628 |
| advent17 | 20.67 | 22,000 |
| advent18 | 0.06 | 14,060 |
| advent19 | 18:54.12 | 14,295,324 |
| advent20 | 15.04 | 13,940 |
| advent21 | 0.40 | 12,680 |
| advent22 | 0.23 | 15,908 |
| advent23 | 6:10.18 | 13,628 |
| advent24 | 2.74 | 74,820 |
| advent25 | 0.01 | 5,896 |
Optimising
As promised above, I've now done some optimising of these solutions. You can read about how I optimised day 15, day 16, day 19, and day 23. But if you just want the results, I've summarised them below, including how many times faster the new version is than the old.
| Program | Original elapsed time (s) | Original max memory (kb) | Optimised elapsed time (s) | Optimised max memory (kb) | Speedup |
|---|---|---|---|---|---|
| advent15 | 2:17.27 | 18,101,260 | 0:02.36 | 672,592 | 58 |
| advent16 | 2:24.64 | 45,628 | 0:10.77 | 149,876 | 13 |
| advent19 | 18:54.12 | 14,295,324 | 0:06.77 | 1,073,516 | 168 |
| advent23 | 6:10.18 | 13,628 | 0:06:49 | 17,604 | 57 |
Language features
I took a look at the packages and modules I used. (A module is something imported into a Haskell program; a package is a collection of modules downloaded and installed together. containers is a package, but Data.Set is a module.)
| Package | Days of use |
|---|---|
| containers | 16 |
| attoparsec | 14 |
| lens | 14 |
| text | 14 |
| linear | 9 |
| mtl | 7 |
| pqueue | 4 |
| split | 4 |
| array | 2 |
| multiset | 2 |
| data-clist | 1 |
| deepseq | 1 |
| parallel | 1 |
| rosezipper | 1 |
This shows I used containers on most days for things like Sets and Maps, along with attoparsec and text for parsing the input data files. lens got a lot of use, as I now tend to use it for most fiddling with data structures. linear was used to represent points and positions. mtl (monad transformers) was used the few times I used monads in the code (four of them were in the graph-search programs).


I did a similar analysis at the module level.
| Module | Number of uses |
|---|---|
| AoC | 25 |
| Data.List | 16 |
| Data.Text | 14 |
| Data.Attoparsec.Text | 14 |
| Data.Text.IO | 14 |
| Control.Lens | 13 |
| Data.Set | 11 |
| Data.Maybe | 10 |
| Control.Applicative | 10 |
| Linear | 9 |
| Control.Monad.Reader | 6 |
| Data.Map.Strict | 5 |
| Data.Ix | 5 |
| Data.Sequence | 4 |
| Data.List.Split | 4 |
| Data.Char | 4 |
| Data.IntMap.Strict | 3 |
| Data.Array.IArray | 2 |
| Control.Monad.State.Strict | 2 |
| Data.MultiSet | 2 |
| Data.Ord | 2 |
| Data.PQueue.Prio.Max | 2 |
| Data.PQueue.Prio.Min | 2 |
| Data.Tree | 1 |
| Data.Tree.Zipper | 1 |
| GHC.Generics | 1 |
| Control.DeepSeq | 1 |
| Data.Monoid | 1 |
| Data.IntMap | 1 |
| Data.Foldable | 1 |
| Data.CircularList | 1 |
| Control.Parallel.Strategies | 1 |
| Control.Monad.Writer | 1 |
| Control.Monad.RWS.Strict | 1 |
| Prelude | 1 |
This shows that List, Set, and Maybe are the most-used data structures. I was a bit surprised that Map only occurred eight times (five times as Map, thrice as IntMap). Prelude occured once, to hide a standard import.


As with the previous couple of years, none of the packages and modules are "exotic": there's no use of rings or groups, no constraint solvers, no uses of number theory. I used monoids once because I felt like, more than the problem deserved it.
See also
A few other people are blogging about their experiences with Advent of Code. So far, I've found:
If you know of others, please let me know!
Code
You can get the code from my locally-hosted Git repo, or from Gitlab.